埋点设计流程
一篇完整的数据埋点文档通常包括三个模块,分别为指标体系、标签场景和标签体系。通过产品业务分析和指标定义,我们能够梳理出一套较为完善的指标体系;标签场景,也即通过事件设计总结出指标体系要适用于哪些场景,也即我们提到过的 事件–用户模型。最后是标签体系,通过属性设计完善整个标签系统,以便于后续的上线、维护与更新。
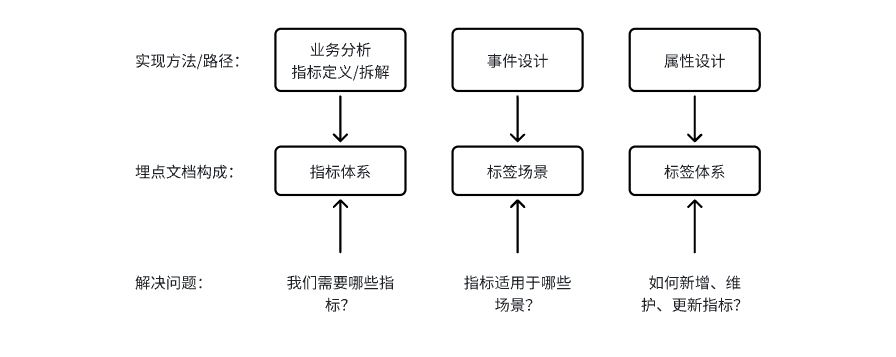
结合上面这个图表,我们可以发现数据埋点文档并不是写完就结束了,相反,它是一个动态更新的文档。产品版本的更新迭代,其中包含了新增、下线、修改的流程,数据埋点也需要跟随版本进行相应调整。
埋点设计流程
业务分析
想象你在上数学课,老师让你用尺子来测量桌子的长度。这里,尺子就是一种“工具”,用来衡量长度这个“指标”。在更广泛的意义上,指标体系就是一套用来衡量或评价某�些东西的标准或工具。比如在学校里,考试分数就是衡量学生学习成绩的指标。在商业中,可能会用利润、市场份额等来衡量公司的成功。
在前面的几篇文章中,我们并没有深入探讨什么叫做指标体系 (Metric System),在互联网产品的语境下:
指标体系是一套衡量标准,用于评估产品的性能、用户行为和市场表现等关键方面。
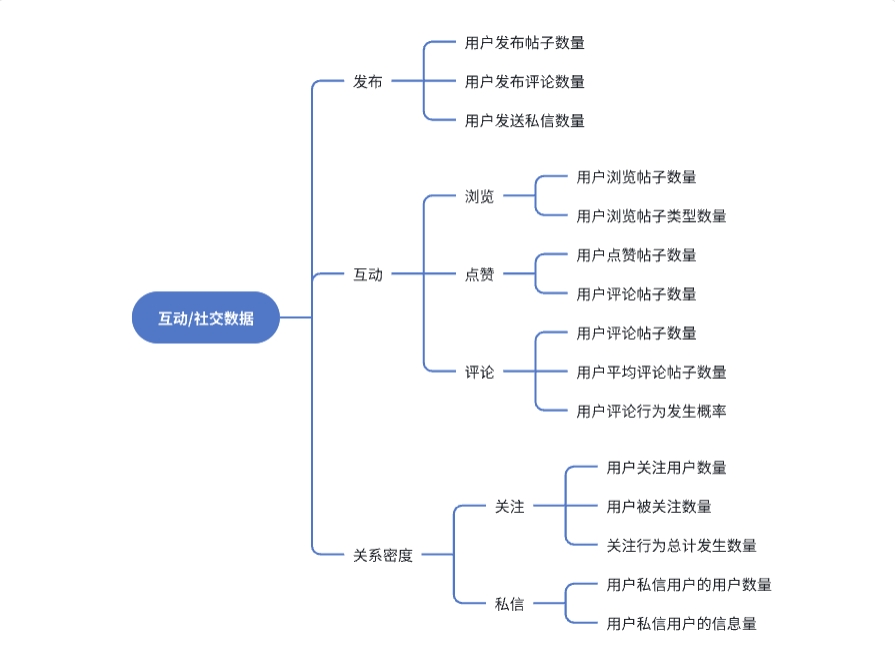
简单来说,一个产品功能好不好,一个产品盈利数据多不多,都可以通过指标体系进行衡量。以社交产品为例,我们可以得到一套简易的指标体系。
那么,如何构建指标体系呢?一般来说,指标体系的构建由两个方面构成,分别是业务分析和指标定义。在业务分析的环节,产品经理主要的工作就是梳理业务流程,以及每个业务流程下的用户路径和细分场景。一般思路是根据用户在产品上具体的操作步骤,来定义用户行为路径。
比如在电商产品交易的场景中,核心操作步骤是用户在商品信息流中点击进入商品详�情页,再到确认订单页、支付页等页面。如下图所示:
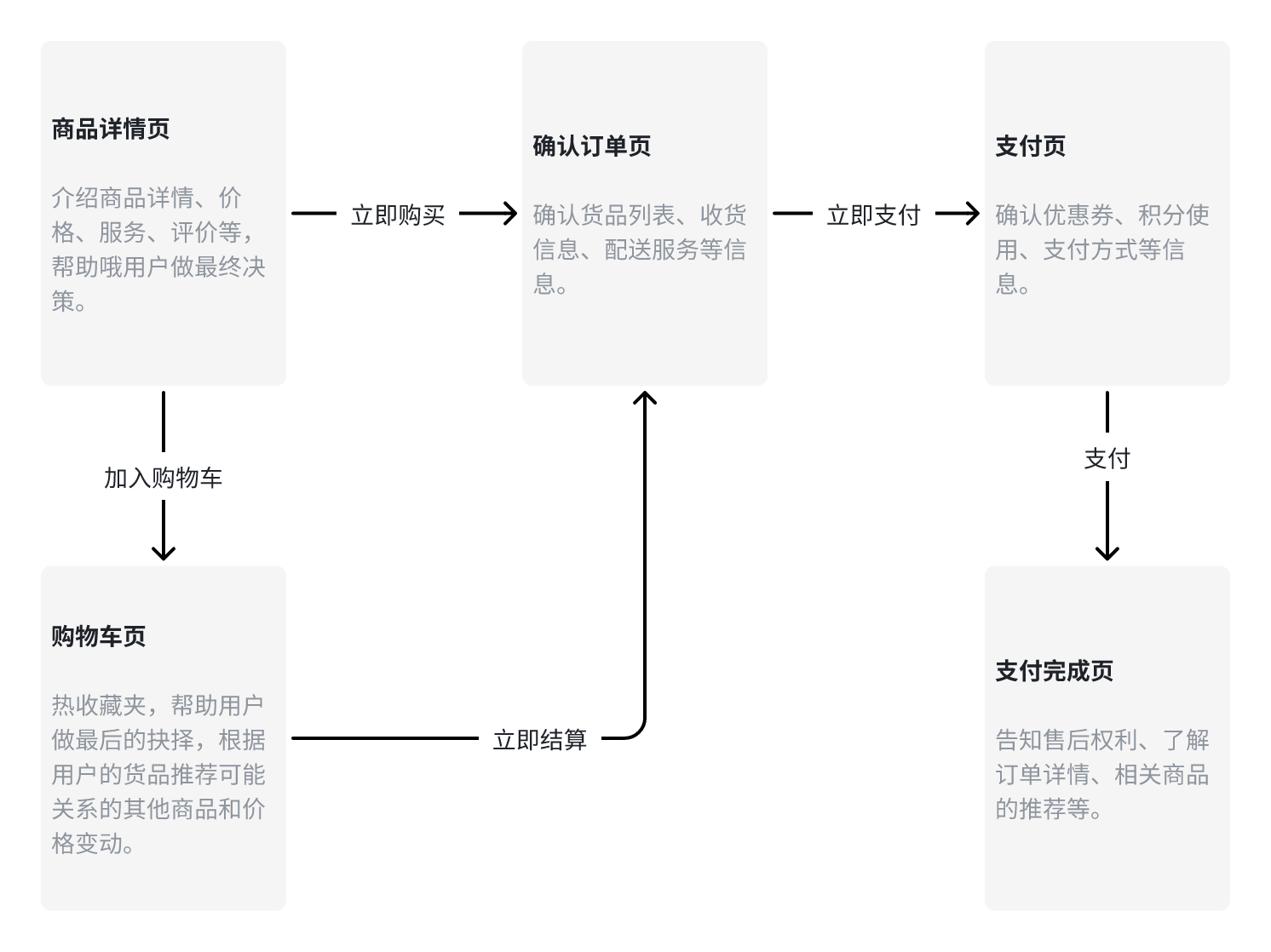
那么,我们就可以把业务拆解为点击商品详情页,点击商品购买按钮、进入商品支付页、完成支付四个环节。在点击商品详情页这个环节中,我们可以通过用户是从哪个模块、栏目,在信息流中的哪个位置进入的商品详情页,来分析用户对页面布局的敏感程度。这样就能够知道哪些位置对用户来说更具吸引力。
又比如,在进入商品支付页(确认订单页)的环节,通过统计用户历史购买记录,来分析置入哪些关键词提示更能促进用户完成交易,在支付模块,则可以根据用户常用的支付手段,来调整支付方式的排序等等。
指标定义
完成业务分析之后,需要结合业务分析目标思考,每个细分的业务过程可以有哪些指标来分析。
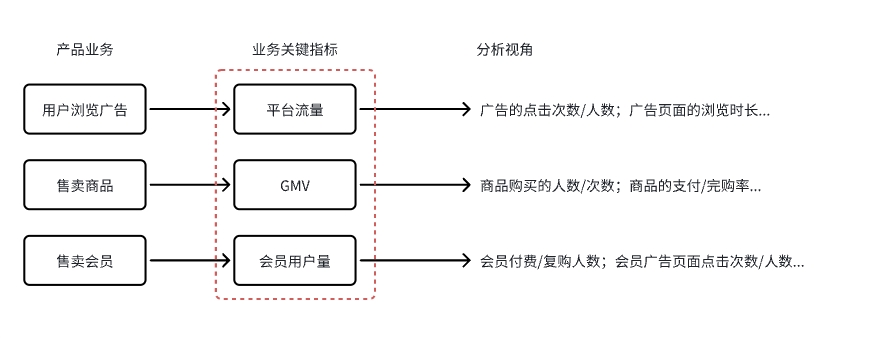
举几个例子:
在电商产品的信息流浏览场景中,常见的分析视角有:
- 用户对不同商品的需求情况怎么样?相关指标有:信息流中不同商品的点击次数/人数/频次;
- 信息流商品的健康度如何?相关指标有:信息流商品整体的点击人数/次数、商品点击率/点击频次;商品详情页返回结束数/停留时长;信息流的用户停留时长;
- 信息流中的商品是否能够满足用户需求?相��关指标有:加购信息流商品的人数/次数、商品的下单数/完成支付数;
在券商产品的行情浏览场景中,常见的分析视角有:
- 行情功能是否能够满足用户需求?相关指标有:除 沪深京Tab 外,行情功能Tab 的点击次数/人数;其他(全部)中按钮的点击次数/人数/频率;其他入口的点击次数/人数;
- 行情功能的健康度如何?相关指标有:功能点击次数/人数;(非)交易时间页面停留时长;个股/资讯等子功能的点击次数/人数;
- 行情功能是否有效引导用户交易?相关指标有:添加自选的次数/人数;下单交易(买入/卖出)按钮的点击次数/人数;
此时,我们就完成了指标定义。
事件设计
在事件设计环节,我们解决的是标签场景设计的问题。什么是标签场景(Tagging Context)?这个概念有点像你在社交媒体上给照片贴标签。假设你去旅行,拍了很多照片,回来后你可能会给这些照片贴上“旅行”、“海滩”、“美食”等标签。标签场景就是指在特定的环境或情境下,给信息、数据或事物贴上标签,以便于理解和分类。
我们还是使用上述提到的电商和券商产品来举例子。现在我们已经得到了部分指标体系,我们需要确定标签场景,让指标发挥作用。
1、电商产品事件(用户行为):
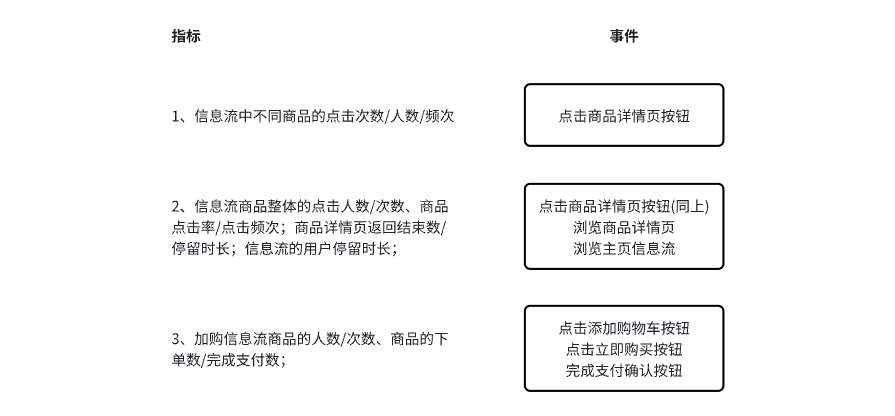
2、券商产品事件(用户行为):
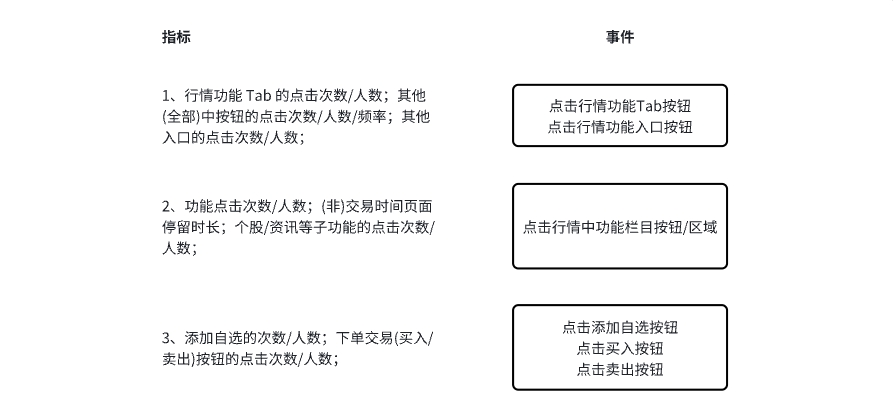
单独事件设计
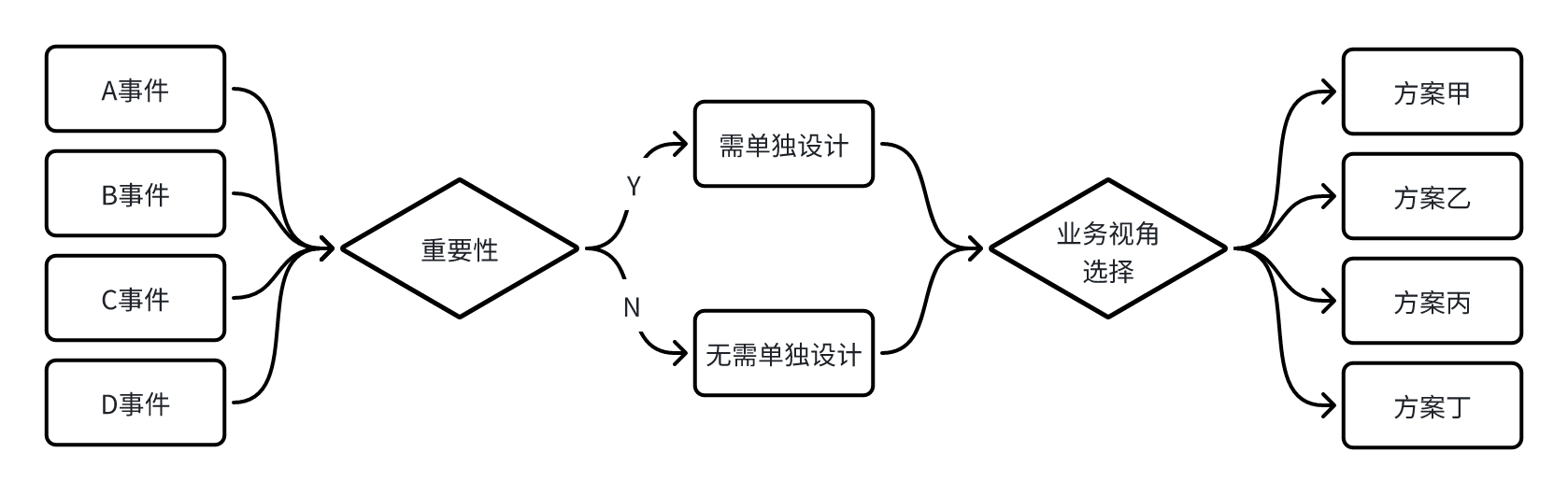
在埋点设计中,还有一个重要的问题需要考虑:针对某个具体的行为是否需要设计单独的事件?比如点击搜索按钮这个行为是否可以用全埋点APP元素点击这个事件采集,还是需要有一个单独事件点击搜索按钮事件去采集?
我想很多产品经理都不会认真思考这个问题,一方面是没有思考的必要,另一方面是埋点方式经常采用直觉去做出选择。判断点击事件的方式也比较简单,就是看这个事件的重要性。一般来说,涉及到核心业务和指标都需要单独设置事件采集。
1、对于重要的点击事件
重要点击事件单独设置事件采集,而不使用诸如APP元素点击或Web元素点击等的全埋点事件。重要的点击事件往往需要记录更全面、更精细的字段,需要根据具体的点击事件的类型以及个性化属性,进行归类采集;常见的点击事件有 Banner 位点击、Icon 点击、频道 Tab、功能重要操作点击等事件。以下表为例,在搜索中点击证券产品就可以单独设置事件进行采集,一般事件内容也较为复杂。
| 事件显示名 | 属性英文变量名 | 属性显示名 | 数据类型 | 属性值示例或说明 |
|---|---|---|---|---|
| 搜索_产品点击 | source_page | 来源页面 | STRING | 首页、行情、其他 |
| search_content | 搜索内容 | STRING | 搜索框内输入的内容 | |
| search_type | 搜索类型 | STRING | 手动输入、历史搜索 | |
| product_name | 产品名称 | STRING | ||
| product_code | 产品代码 | STRING | ||
| code_type | 证券类型 | STRING | ||
| market_type | 市场类型 | STRING | 沪市、深市、京市、股转、港交所 | |
| product_type | 产品类型 | STRING | A股、B股、债券、国债逆回购、ETF基金、reits基金、普通基金(除reits、etf之外的基金)、港股、期权、期货、板块、指数、基金理财、股转股票 |
2、对于相似的行为事件
相似行为事件,如 信息流广告点击 和 Banner广告位点击 。这两个行为需要记录复杂的属性,已经确定要设置单独事件,但两个事件采集的字段非常相似,都需要采集广告 ID、广告名称等字段,那么要采用以下哪种方案呢?
方案A
| 事件 | 事件属性 | 事件属性说明 |
|---|---|---|
| 信息流广告点击 | 所属页面 | 记录广告所属页面名称 |
| 所属模块 | 记录广告所属页面模块名称 | |
| 广告名称 | 记录广告名称 | |
| 广告资源ID | 记录广告资源ID | |
| 跳转链接 | 记录点击广告位跳转的链接URL | |
| 排序 | 记录信息流广告在推荐列表上的排序,从 0 开始记录记录 | |
| 推荐策略 | 信息流广告的推荐策略名称 | |
| Banner 广告位点击 | 所属页面 | 记录广告所属页面名称 |
| 所属模块 | 记录广告所属页面模块名称 | |
| 广告名称 | 记录广告名称 | |
| 广告资源ID | 记录广告资源ID | |
| 跳转链接 | 记录点击广告位跳转的链接URL |
方案B
| 事件 | 事件属性 | 事件属性说明 |
|---|---|---|
| 广告点击 | 所属页面 | 记录广告所属页面名称 |
| 所属模块 | 记录广告所属页面模块名称 | |
| 广告名称 | 记录广告名称 | |
| 广告资源ID | 记录广告资源ID | |
| 跳转链接 | 记录点击广告位跳转的链接URL | |
| 排序 | 记录信息流广告在推荐列表上的排序,从 0 开始记录记录 | |
| 推荐策略 | 信息流广告的推荐策略名称 | |
| 广告类型 | 如果是信息流广告,记录信息流广告;如果是 Banner 广告,记录Banner广告 |
当出现这种情况时,我们往往要回到业务去进行分析。如果在后续的数分�中,业务需要区分信息流和 Banner 广告点击,或者需要单独将这两者合并统计。那么我们会采用 A 方案。但如果后续业务并不会看数据,那就选择 B 方案。在事件设计中,首先通过重要性判断需要单独设计的事件,其次以业务视角,选择合适的采集方案。
数据采集细节
在事件设计中,除了描述事件的属性和说明,还需要讲清楚数据的采集时机和采集端。这非常重要,采集时机和采集端看似影响不大,但最终采集的数量很可能天差地别。
举个例子,假如我们设计了一个 信息流商品曝光 的埋点事件,如果不对采集时机进行说明,那么研发小哥应该在商品露出多少时进行采集呢?如果研发在商品露出一个边边的进行采集上报,但业务实际想要的是完全露出才展示上报,那么最终采集的数据会出现非常大的差距。
再比如 商品详情点击 的埋点事件,如果不明确采集时机,那么点击事件应该是一点击就采集上报,还是点击之后停留 2s 后才上报(排除误触情况),又或者是页面完成加载后再上报呢(排除页面加载失败情况)?
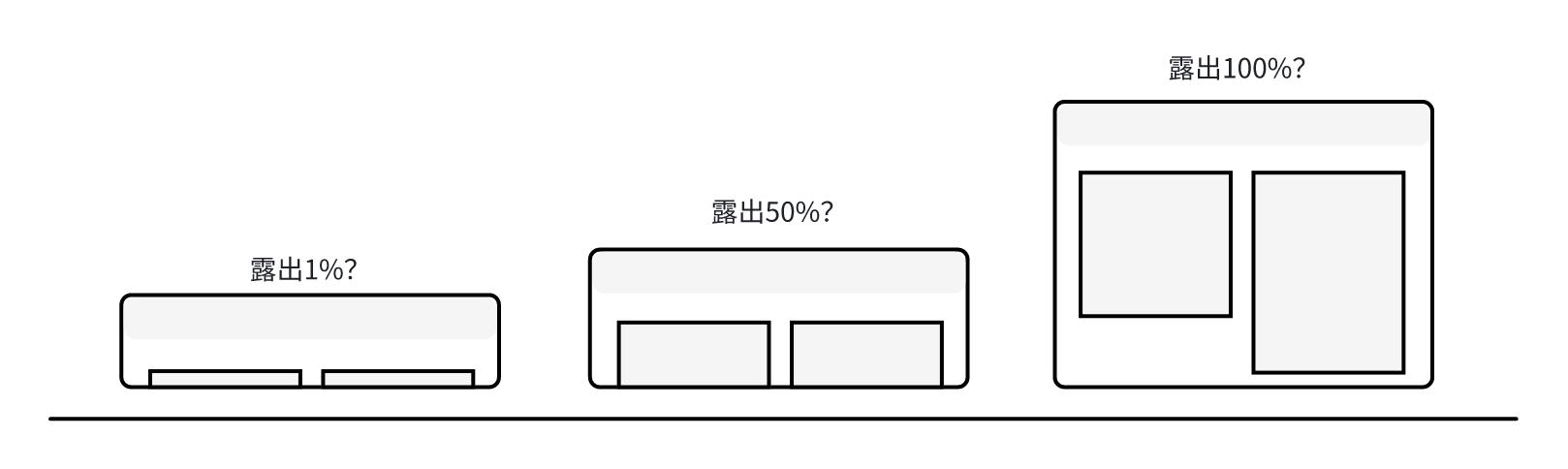
除了明确采集时机之外,对于通过哪一端进行采集也同等重要,选择不同端的采集行为同样也会导致数据出现相当大的差异。在事件设计时需要描述清楚在什么样的情况下会触发事件数据的采集。
从事件上报的触发逻辑上面来讲,可分为前端触发上报、前端获取后端汇总结果后上报、后端触发上报、后端获取前端属性后上报四个比较类别,如下表所示:
| 方式 | 说明 |
|---|---|
| 前端触发上报 | 事件埋点所有信息由前端产生,由前端上报 |
| 前端获取后端汇总结果上报 | 事件埋点部分属性由前端产生,部分由服务端产生,后者产生的信息传到前端,汇总后由前端上报 |
| 后端触发上报 | 事件埋点所有信息由后端产生,由后端上报 |
| 后端获取前端属性后上报 | 事件埋点部分属性由后端产生.部分由前端产生,后者产生的信息传到后端,汇总后由后端上报 |
以淘宝下单流程中的购买成功为例,详细介绍下单埋点事件的触发逻辑类型:

1、前端触发,上报
前端触发立即上报,也就是用户点击立即付款按钮就触发,这是最常见的前端采集方式。这种方式能够衡量用户是否有意愿支付。
2、前端获取后端汇总后上报
这种方式通常用于获取用户操作的结果。也即用户点击立即付款按钮后,我需要知道后端返回的结果,来判断用户是否支付成功,以及在失败情况�下的报错情况。为了满足这一业务目的,则必要等到前端拿到后端服务器处理结果再进行上报。
3、后端触发,上报
后端触发上报的方式,是指后端处理后直接上报,跳过了前端。比如用户点击立即付款按钮,出现支付结果后触发上报。这种方式的好处在于不会漏报数据,但由于是后端直接上报,所以基本上拿不到用户的设备终端及软硬件环境属性,比如用户在支付时使用的是什么设备、网络环境是什么等信息。
4、后端获取前端属性且触发上报
这种情况就是为了解决后端埋点的软硬件环境属性问题,让前端在用户点击立即支付按钮时,将相应的属性一并传回服务器,服务器发生支付成功时,带上相应的前端属性上报数据;当然这种方式理论上时数据准确度、完备性最高的,但同时这种方式的采集成本会比较高,意味着所有端的前后端接口需要做变更,建议是只在数据准确性、前端属性获取两个需求都非常强烈时采用。
属性设计
数据埋点的属性设计,核心目的是为了搭建好标签体系,在后续的维护中,埋点属性还需要支持增删改查的能力。属性设计就是埋点设计的最后一个步骤。
什么是标签体系(Tagging System)?
标签体系可以理解为一整套给事物贴标签的规则和方法。就像图书馆里的书都按照某种系统来分类和编码,方便你找到你需要的书。在标签体系中,每个标签都有其特定的含义和用途,这样可以帮助人们更有效地组织和检索信息。
一般来说,标签体系长下面这样:
| 一级类目 | 二级类目 | 标签 | 标签英文名 | 属性值 | 属性值类型 | 标签定义 | 是否可配置 | 实际 |
|---|---|---|---|---|---|---|---|---|
| 业务特征 | 风险倾向 | 账户当前风险类型 | risk_cur_type | 高风险,中高风险,中风险,中低风险,低风险,混合型 | STRING | ✅ | x | |
| 短期风险倾向类型 | risk_pre_s_term | 高风险,中高风险,中风险,中低风险,低风险,混合型 | STRING | ✅ | x | |||
| 长期风险倾向类型 | risk_pre_l_term | 高风险,中高风险,中风险,中低风险,低风险,混合型 | STRING | ✅ | x | |||
| 功能业务 | 历史参与过 | 历史使用过L2十档行情 | his_L2 | BOOL | ✅ | |||
| 具备参与条件 | L2十档行情参与资格 | L2_qual | BOOL | |||||
| 当前状态 | L2行情开通 | is_L2 | BOOL | |||||
| 7天功能活跃 | 7天内查看过L2十档行情 | L2_7 | BOOL | ✅ | ||||
| 交易业务 | 产品偏好 | 投资品种偏好 | inv_type_pre | 股票A股,股票B股,股票H股,新三板,场内基金,债转股,国债逆回购,混合型 | STRING | ✅ | ✅ | |
| 历史参与过 | 历史购买过股票 | his_stk | BOOL | ✅ | ||||
| 交易偏好 | 股票概念偏好类型 | stk_cpt_pre | 5G,钢铁,知识产权,军工,食品,机械,国企改革,智能识别 | STRING | ✅ | x | ||
| 交易偏好 | 股票行业偏好类型 | stk_ind_pre | 钢铁,房地产,机械,能源,家用电器,计算机,航空运输,批发和零售,电力设备 | STRING | ✅ | x | ||
| 交易偏好 | 股票板块偏好类型 | stk_brd_pre | 港口,保险,酒店,银行,物流,机场,元件,高速公路,专业零售,传播制造,燃气,塑料 | STRING | ✅ | x |
回到上面提到的电商信息流的例子,如果需要深入分析用户在商品信息流中的购买意愿,就需要对比分析不同商品封面图、商品描述的数据表现,哪些封面和标题更吸引用户,进而产生交易行为?那么,对于商品信息流的维度数据,例如信息流中的商品描述、封面图、价格标签等属性就相当关键。
需要强调的是——在属性设计时,除了维度全面之外,还必须保证每个属性都是独立采集。我们还是使用上文展示过的券商产品中搜索_产品点击事件来观察,其中,属性内容都是单一进行采集的。比如搜索内容和搜索类型就不能合并进行采集,如果合并采集,那么子项中的输入内容和输入方式就会十分混乱。同理,如果把市场类型和产品类型合并采集呢?那将是一场噩梦...所以在采集的过程,需要区分属性,以保证后续灵活的下钻分析。
| 属性英文变量名 | 属性显示名 | 数据类型 | 属性值示例或说明 |
|---|---|---|---|
| source_page | 来源页面 | STRING | 首页、行情、其他 |
| search_content | 搜索内容 | STRING | 搜索框内输入的内容 |
| search_type | 搜索类型 | STRING | 手动输�入、历史搜索 |
| product_name | 产品名称 | STRING | - |
| product_code | 产品代码 | STRING | - |
| code_type | 证券类型 | STRING | - |
| market_type | 市场类型 | STRING | 沪市、深市、京市、股转、港交所 |
| product_type | 产品类型 | STRING | A股、B股、债券、国债逆回购、ETF基金... |
以上,我们完成了基础的埋点设计。接下来我们需要将这些埋点设计的内容进行整合,输出一份 DRD 文档,文档中详细描述了满足本次业务需求需要采集多少个事件,每个事件下又包含了哪些属性,每个事件在什么时候触发。下文会通过两个详细的例子,来说清楚埋点设计文档(DRD)应该怎么写。
了解更多
关于埋点设计中涉及的业务分析、指标定义、事件设计和属性设计,这四个步骤最终会形成埋点设计文档中最重要的三个组成部分,分别是指标体系、标签场景和标签体系。
PS:本篇文档内容仅以大家最熟知的电商和作者所从事的券商行业示例,关于更多行业和内容,可以参考神策数��据的行业解决方案,里面提供了不同行业的埋点设计文档案例,希望对大家有所帮助~